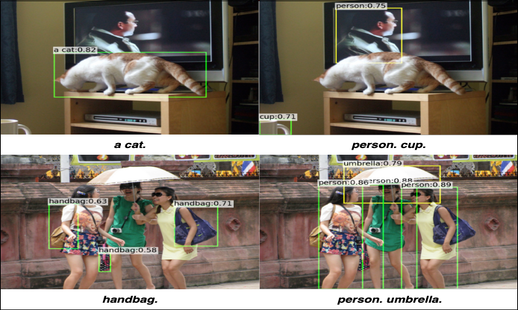
REC Examples

We introduce VoLTA (Vision-Language Transformer with weakly-supervised local-feature Alignment), a new vision-language pre-training (VLP) paradigm that only utilizes image-caption data but achieves fine-grained region-level image understanding, eliminating the use of expensive bounding box annotations.
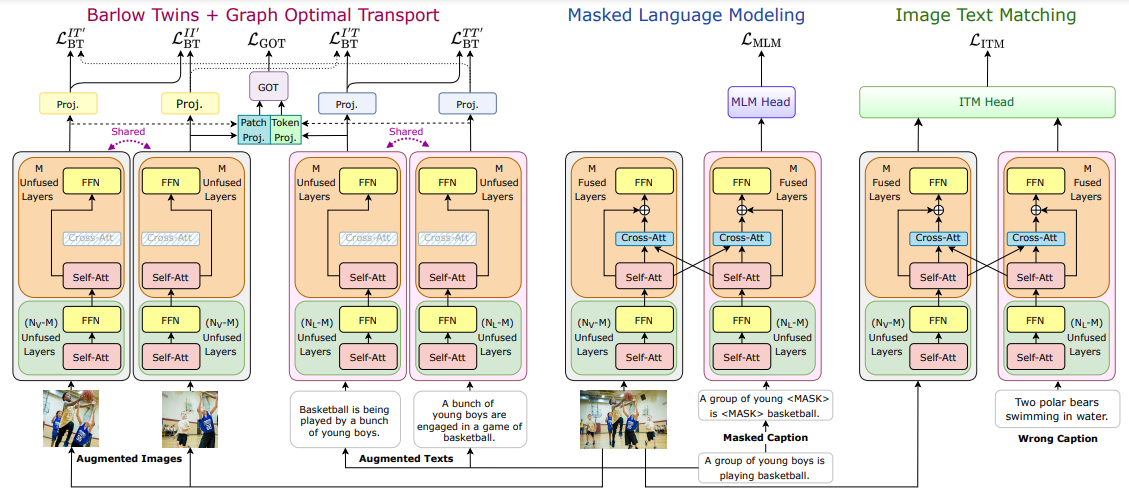
Computation of four different objectives, LBT, LGOT, LMLM, and LITM by the proposed VoLTA framework. Inspired by Dou et al. (2022a), VoLTA inserts cross-modal attention fusion (CMAF) inside uni-modal backbones with a gating mechanism. During VoLTA pre-training, every forward iteration consists of three steps - (i) CMAF is switched off, VoLTA acts as dual encoder, LBT and LGOT are computed. (ii) CMAF is switched on, VoLTA acts as fusion encoder, and image-masked caption pair is fed into the model to compute LMLM. (iii) CMAF is kept on, randomly sampled image-caption pair is fed into the model to compute LITM. Such a fusion strategy results in a lightweight and flexible model compared to using fusion-specific transformer layers.
Vision-language pre-training (VLP) has recently proven highly effective for various uni- and multi-modal downstream applications. However, most existing end-to-end VLP methods use high-resolution image-text-box data to perform well on fine-grained region-level tasks, such as object detection, segmentation, and referring expression comprehension. Unfortunately, such high-resolution images with accurate bounding box annotations are expensive to collect and use for supervision at scale.
In this work, we propose VoLTA (Vision-Language Transformer with weakly-supervised local-feature Alignment), a new VLP paradigm that only utilizes image-caption data but achieves fine-grained region-level image understanding, eliminating the need for expensive box annotations. VoLTA adopts graph optimal transport- based weakly-supervised alignment on local image patches and text tokens to germinate an explicit, self-normalized, and interpretable low-level matching criterion.
VoLTA pushes multi-modal fusion deep into the uni-modal backbones during pre-training and removes fusion-specific transformer layers, further reducing memory requirements. Extensive experiments on a wide range of vision- and vision-language downstream tasks demonstrate the effectiveness of VoLTA on fine-grained applications without compromising the coarse- grained downstream performance, often outperforming methods using significantly more caption and box annotations.
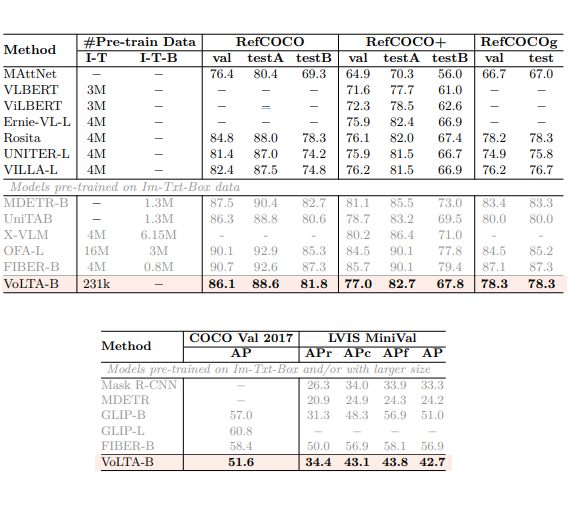
REC, Multimodal OD
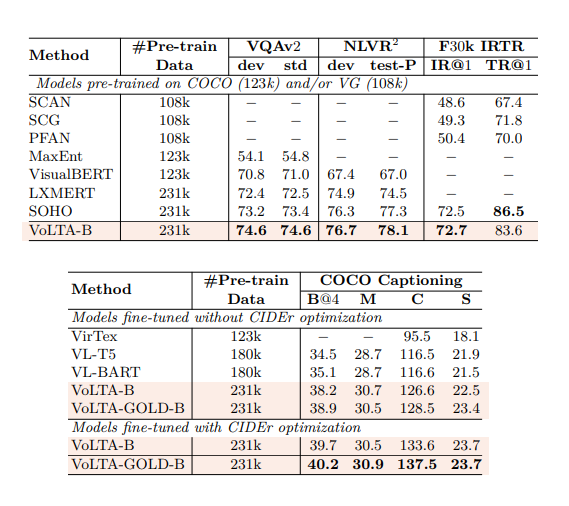
VQAv2, NLVR2, IR/TR. Captioning
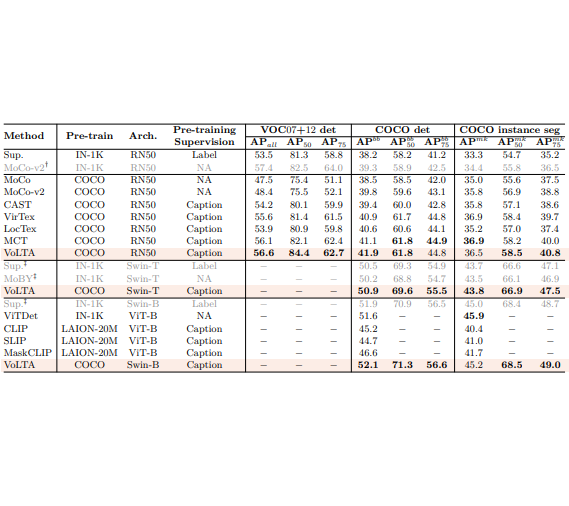
Unimodal OD, Instance Seg
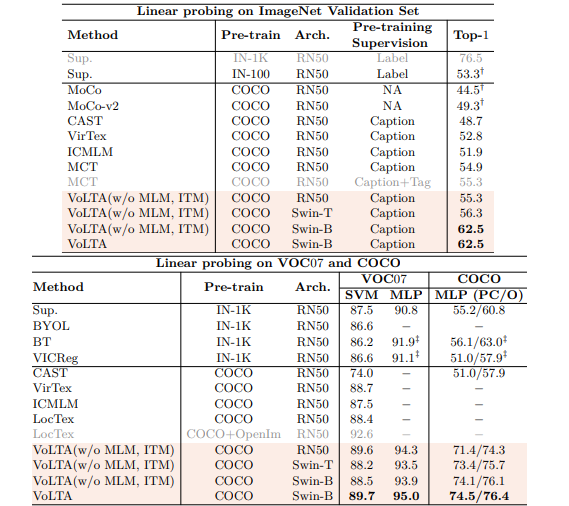
Linear Probing






@article{pramanick2023volta,
author = {Pramanick, Shraman and Jing, Li and Nag, Sayan and Zhu, Jiachen and Shah, Hardik and LeCun, Yann and Chellappa, Rama},
title = {VoLTA: Vision-Language Transformer with Weakly-Supervised Local-Feature Alignment},
journal = {TMLR},
year = {2023}
}