TL;DR: What is ED-VTG?
ED-VTG (Enrich and Detect: Video Temporal Grounding) is a novel method for fine-grained video temporal grounding that leverages multi-modal large language models (LLMs). It works in two stages:
1. Enrich: The model first enriches the input natural language query by adding missing details and contextual cues based on the video content. This enrichment transforms vague or incomplete queries into more detailed descriptions that are easier to ground temporally.
2. Detect: Using a lightweight interval decoder conditioned on the enriched query's contextualized representation, ED-VTG predicts precise temporal boundaries in the video corresponding to the query.
The model is trained with a multiple-instance learning (MIL) objective that dynamically selects the best query version (original or enriched) for each training sample, mitigating noise and hallucinations.
ED-VTG Framework
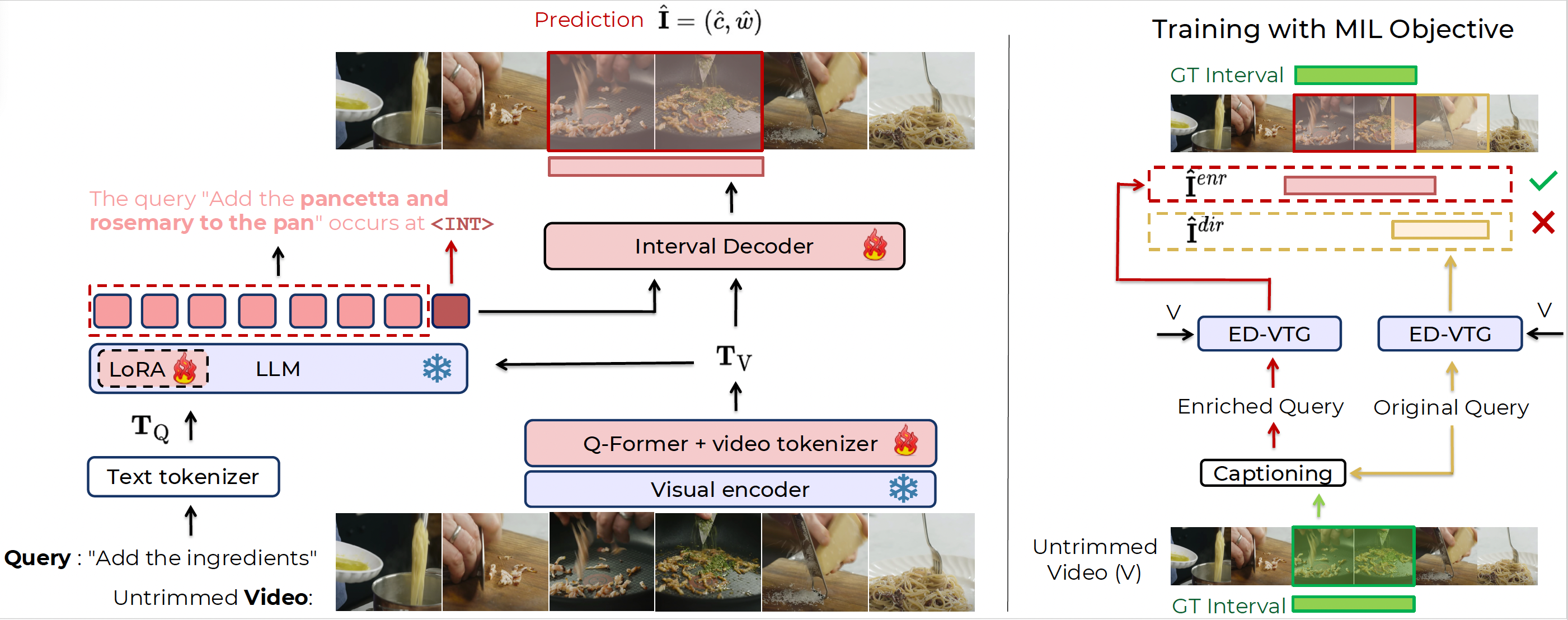
Overview of the proposed Enrich and Detect framework: (left) ED-VTG pipeline: Given an untrimmed video and a query
Q to be grounded, the inputs are first tokenized into video tokens TV and text tokens TQ. The tokens are then fed into an LLM, which
first generates an enriched query by, e.g., filling in any missing details and then emitting an interval token <INT>. The embedding of this
special token is finally decoded into the predicted temporal interval via a lightweight interval decoder. In the example shown here, the
vague input query is enriched into a more detailed one by our model which can be subsequently grounded more easily. (right) Training:
ED-VTG is trained using ground-truth temporal intervals and pseudo-labels of enriched queries, generated by an external off-the-shelf
captioning model, which \(-\) unlike our model at inference time \(-\) has access to the ground-truth intervals. For every sample during
training, the proposed multiple instance learning (MIL) framework allows ED-VTG to assess both the original or the enriched queries and
generate two sets of predictions, \(\hat{I}_{enr}\), the interval predicted using the enriched query, and \(\hat{I}_{dir}\) using the original query. Next, the model
backpropagates using the better prediction (i.e., lower grounding loss). Hence, during training, ED-VTG dynamically learns to decide for
which sample enrichment is necessary and, based on that, performs detection.
Main Results
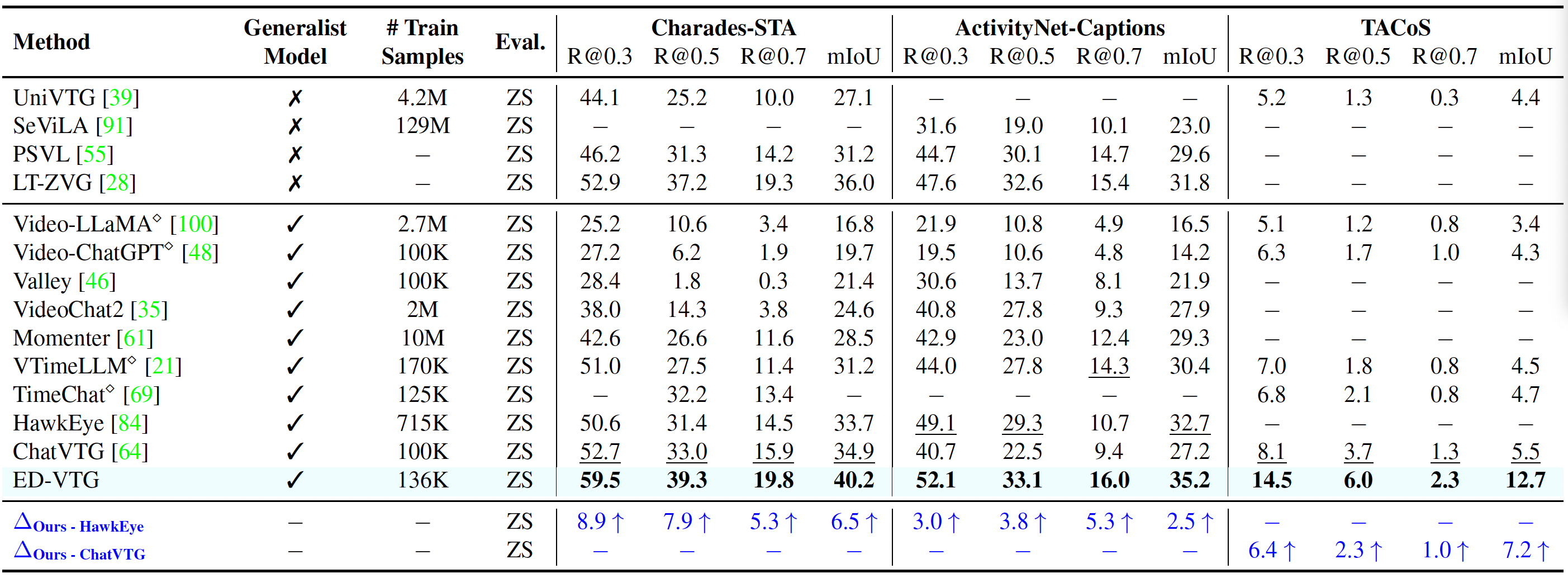
Zero-shot Single Query Grounding
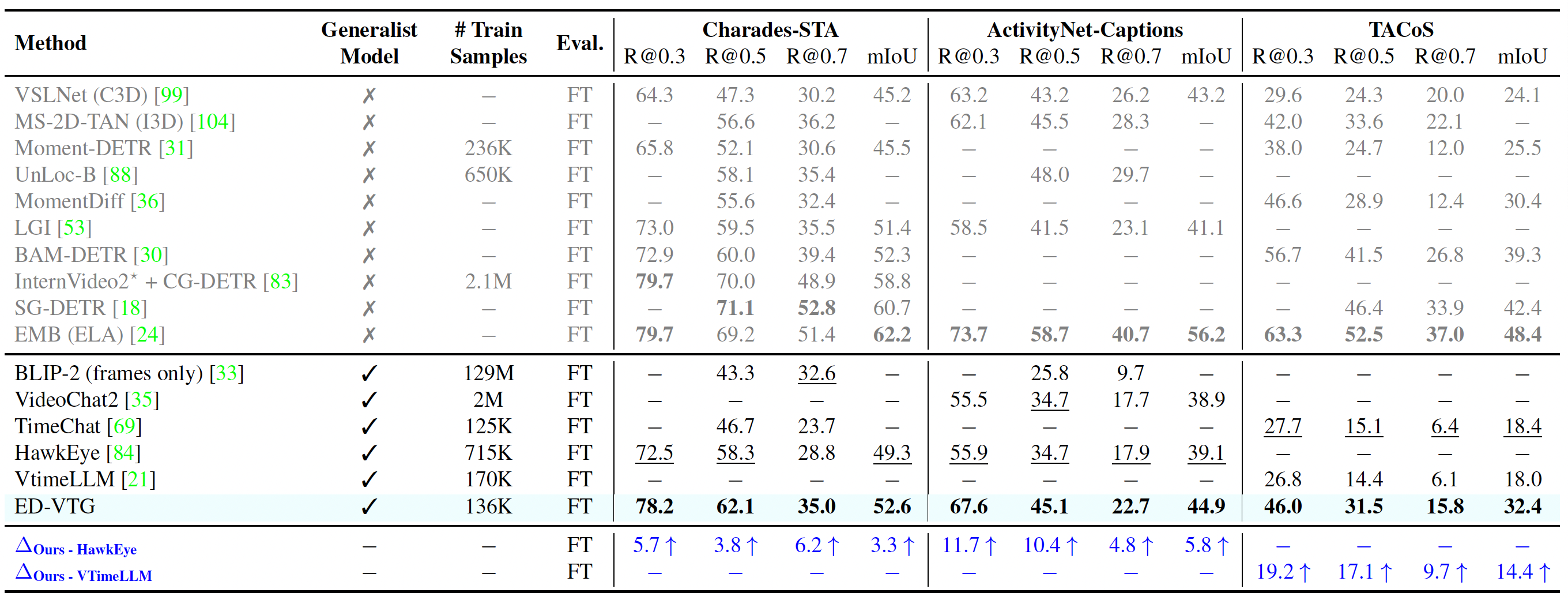
Fine-tuned Single Query Grounding
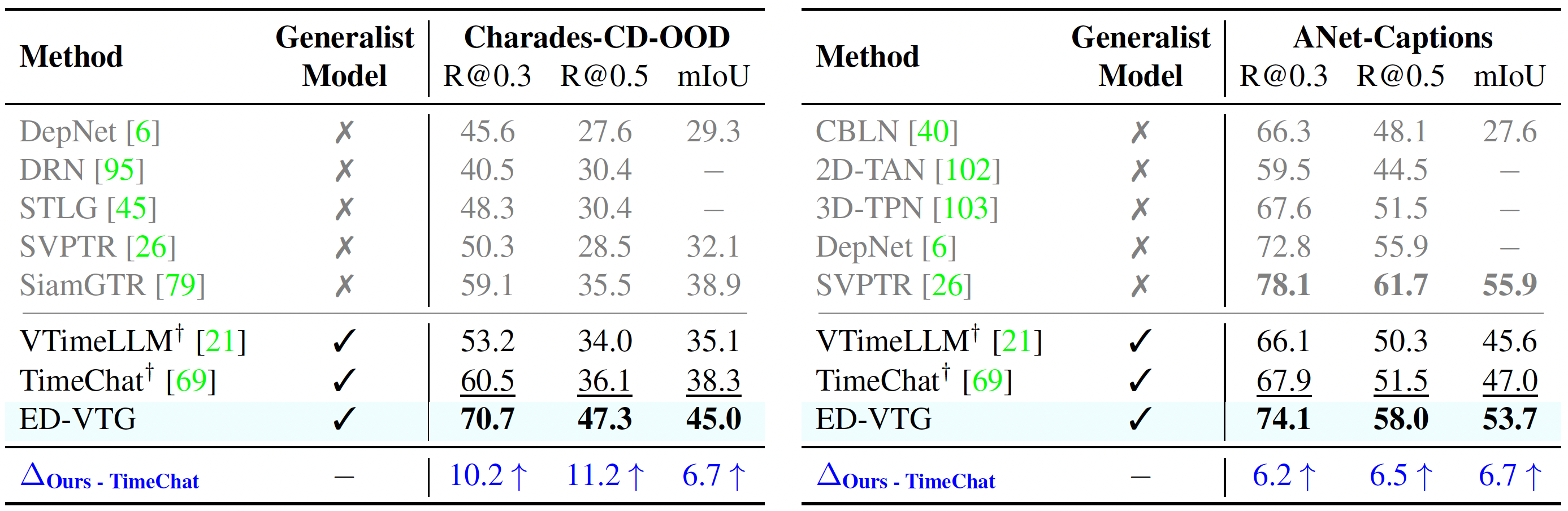
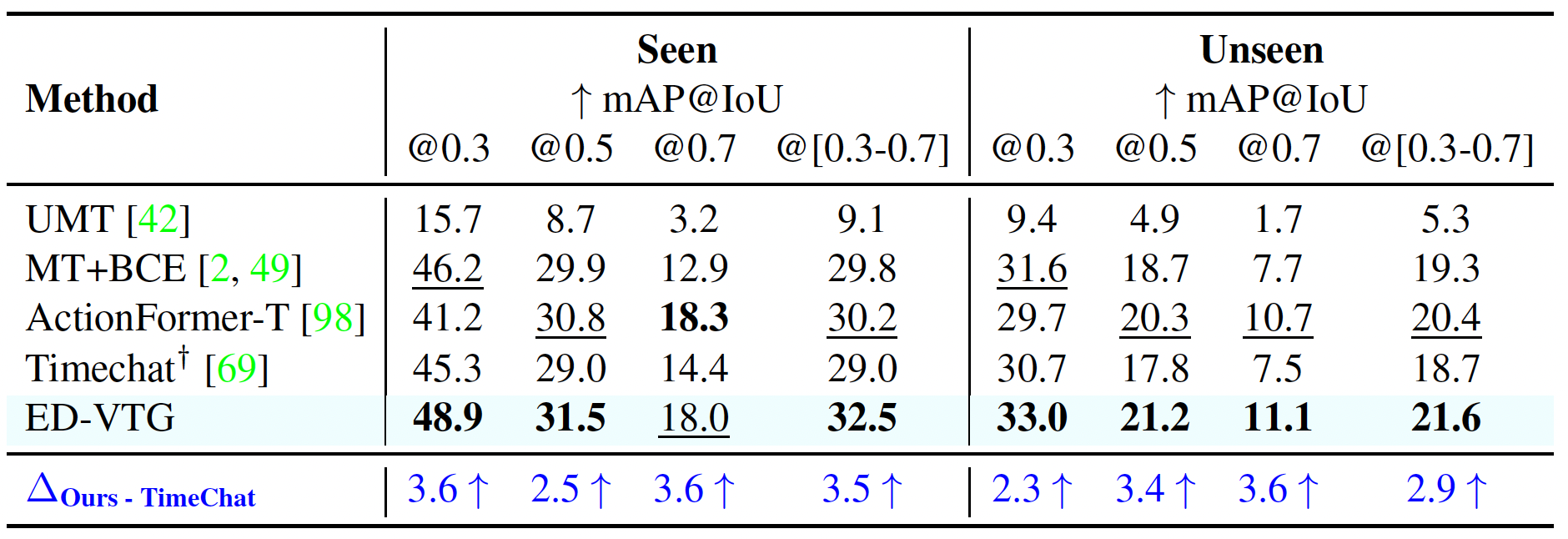
VPG on Charades-CD-OOD and ActivityNet
VPG on TACoS and YouCook2
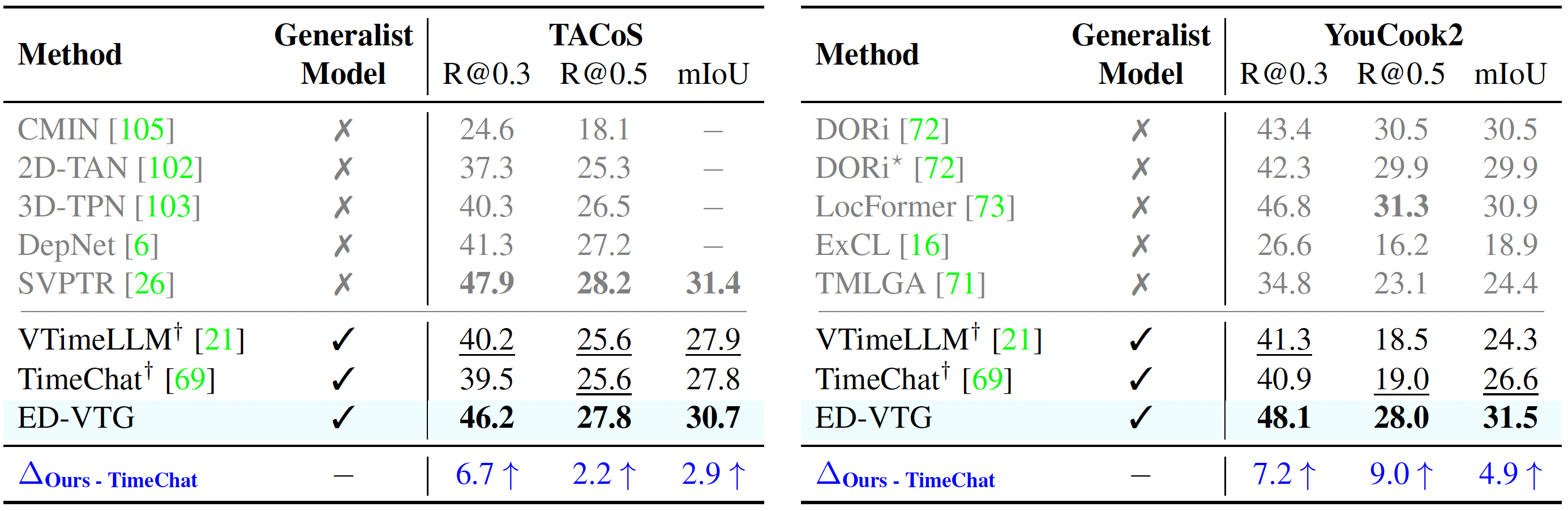
NExT-GQA
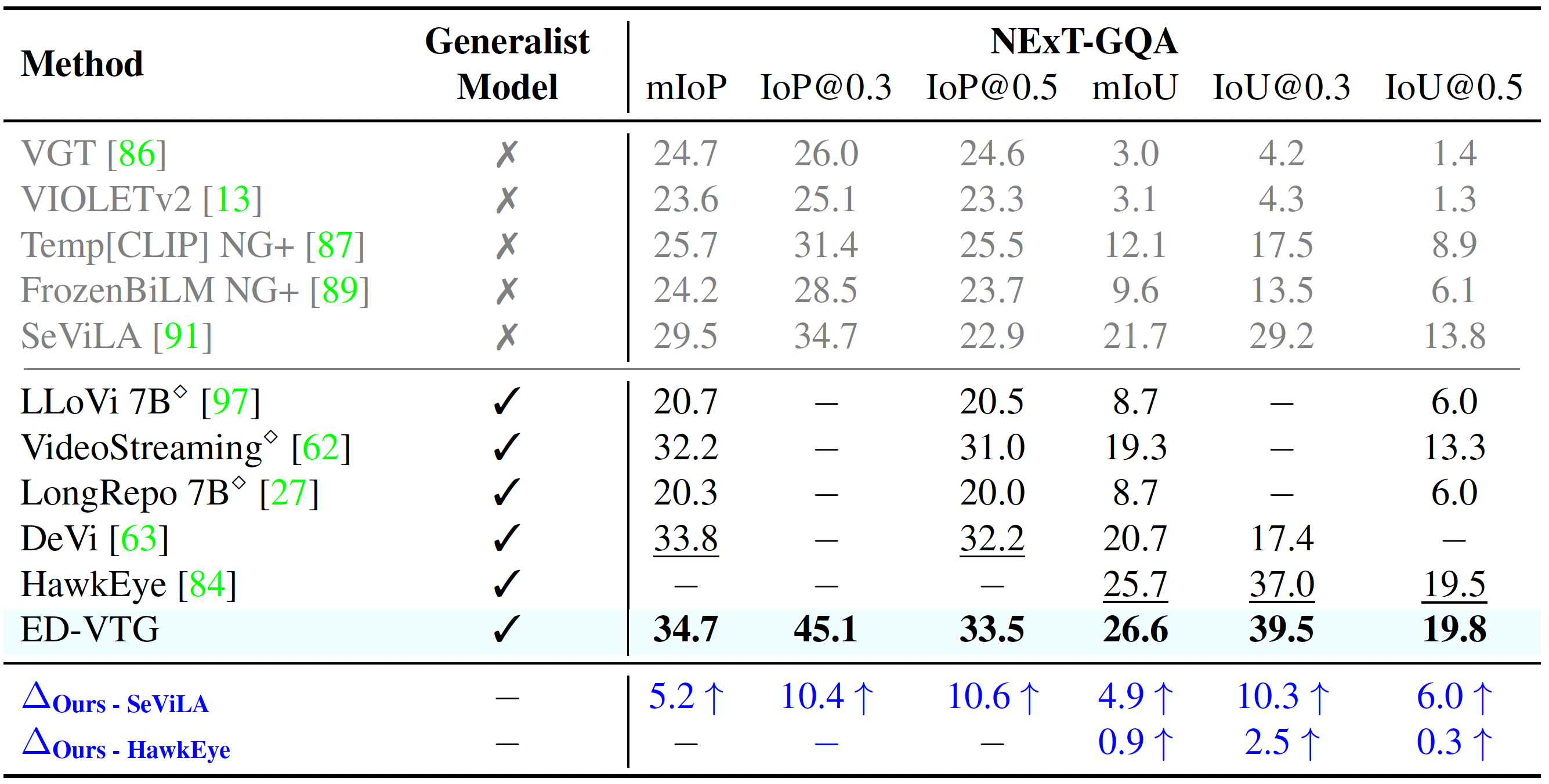
HT-Step
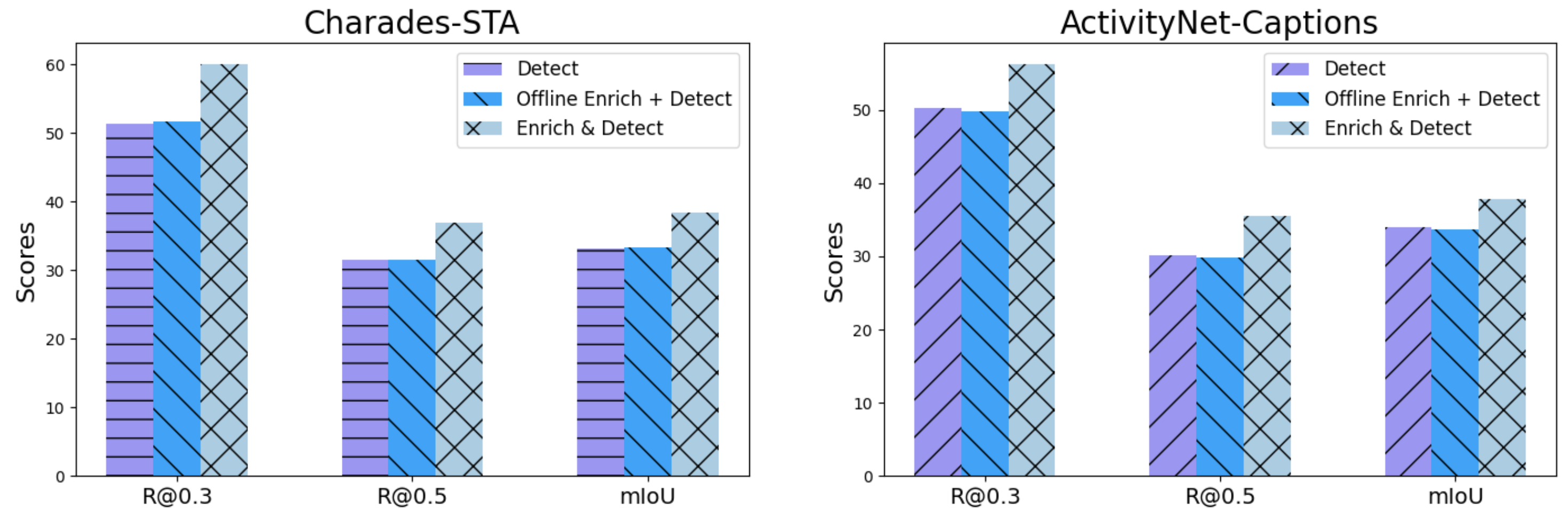
Primary Ablation
The two step enrich & detect framework is more helpful since the trained model learn to perform autonomous enrichment during evaluation.
Qualitative Results
BibTeX
@inproceedings{pramanick2025edvtg,
title={Enrich and Detect: Video Temporal Grounding with Multimodal LLMs},
author={Pramanick, Shraman and Mavroudi, Effrosyni and Song, Yale and Chellappa, Rama and Torresani, Lorenzo and Afouras, Triantafyllos},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
year={2025}
}