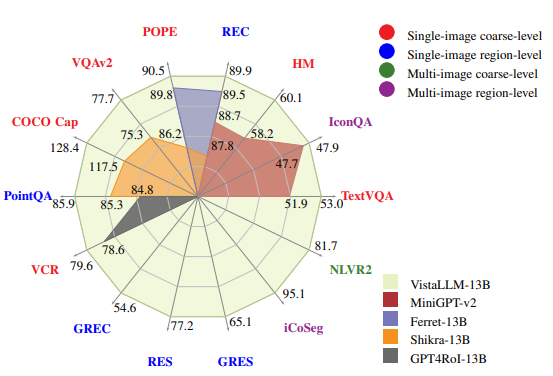
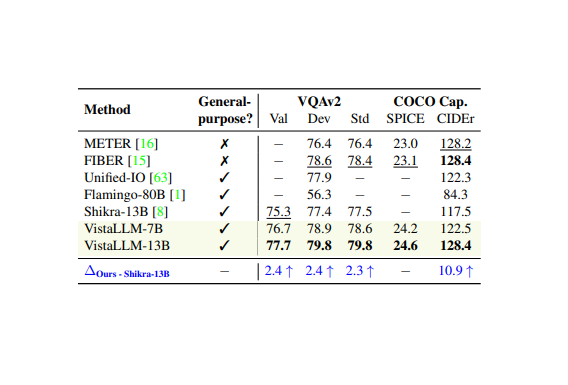
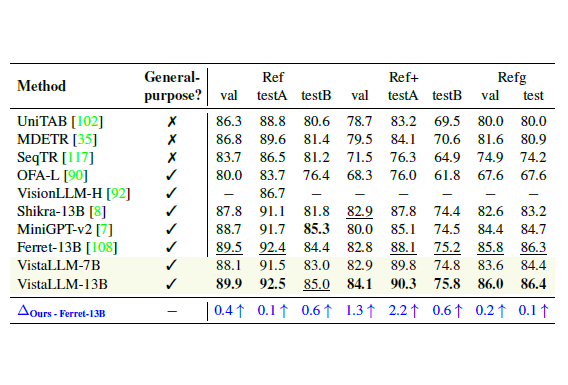
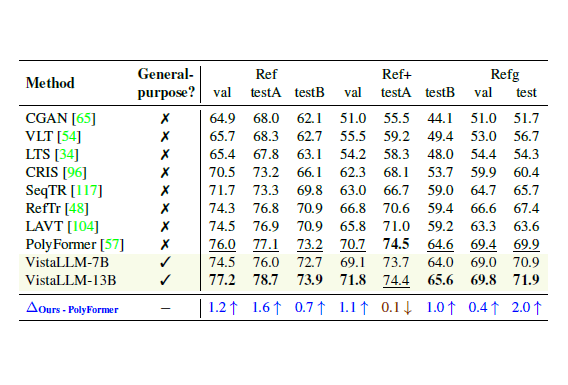
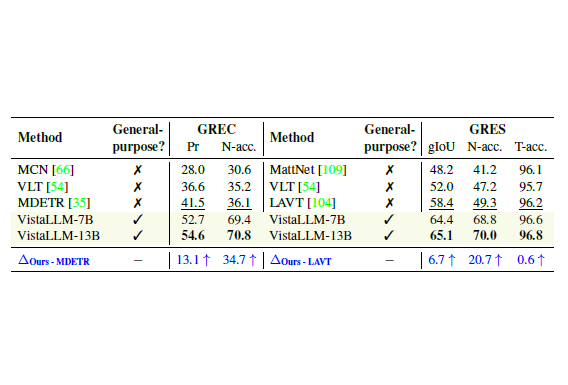
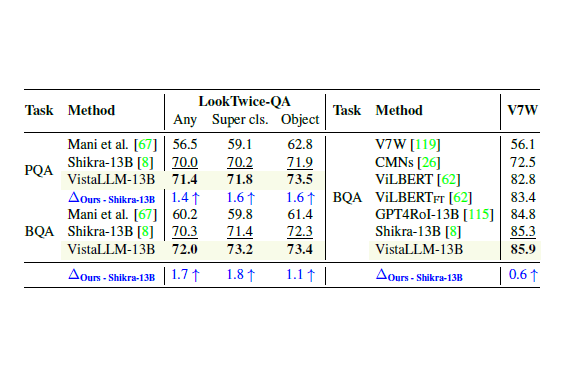
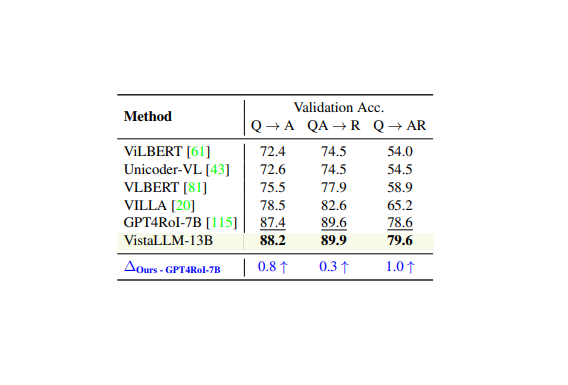
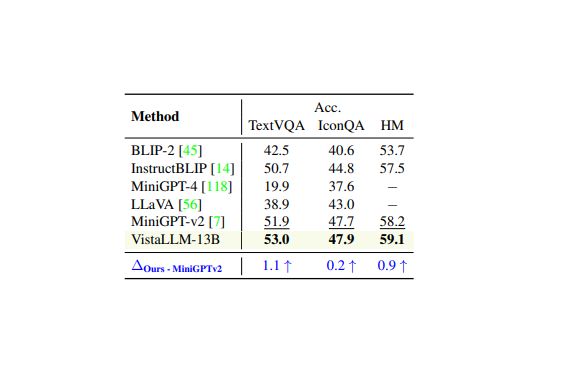
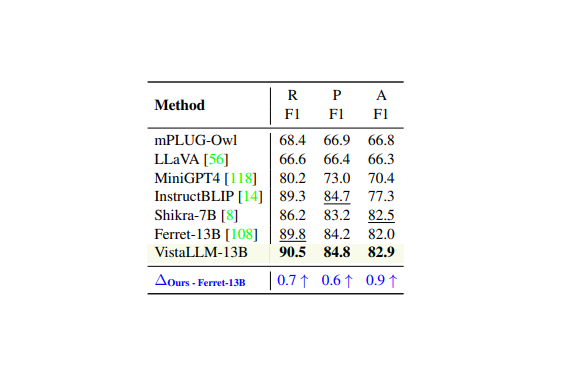
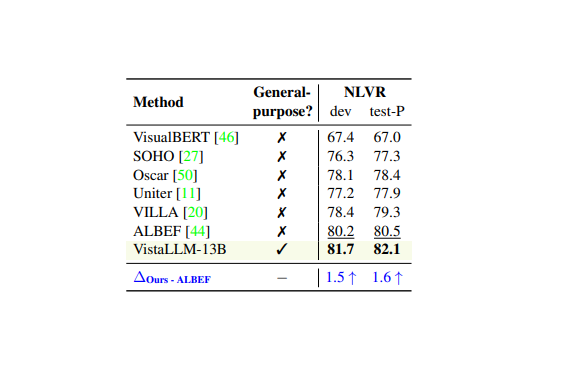
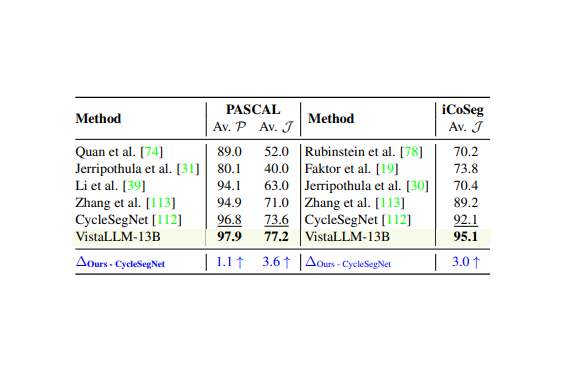
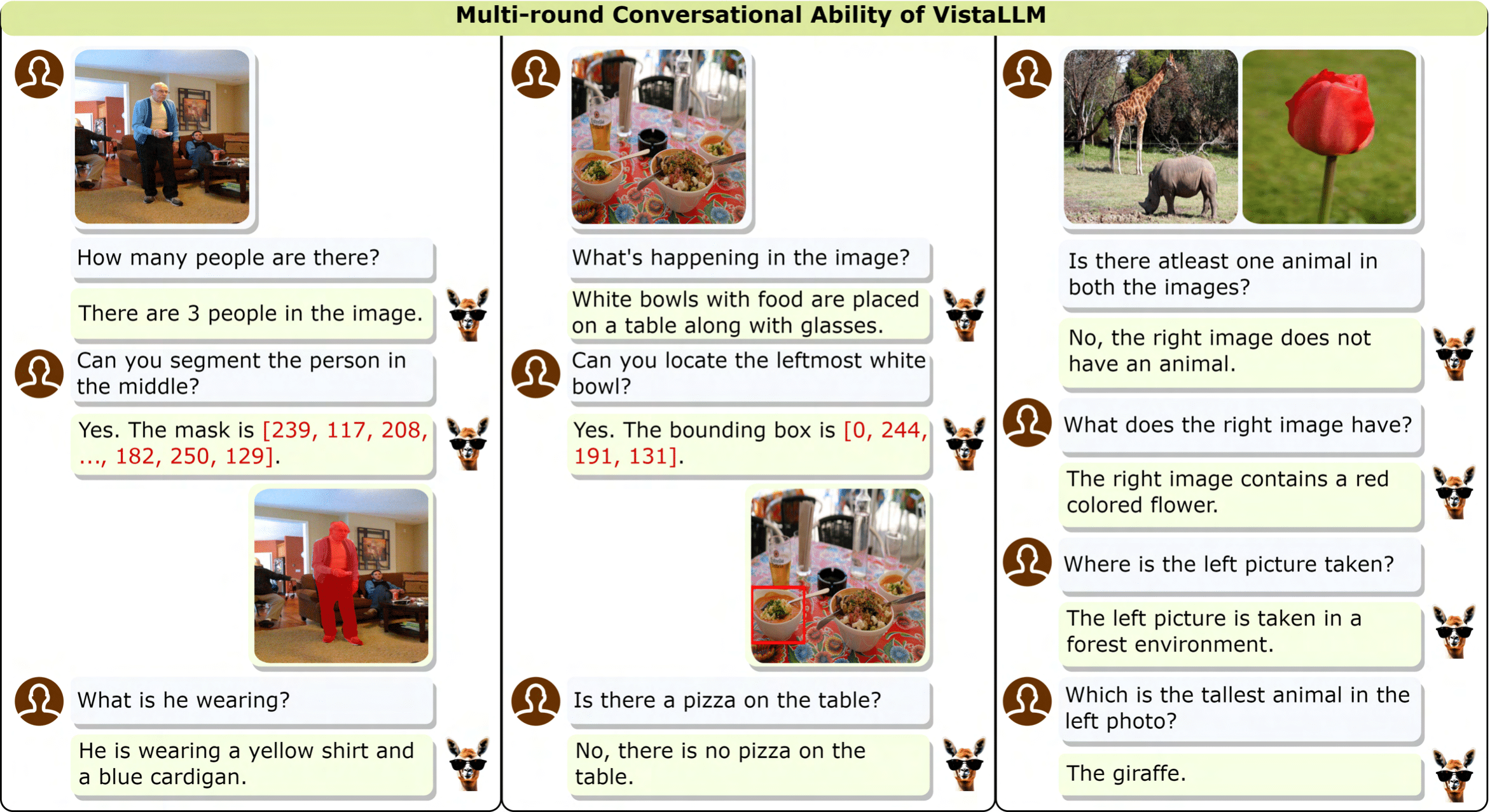
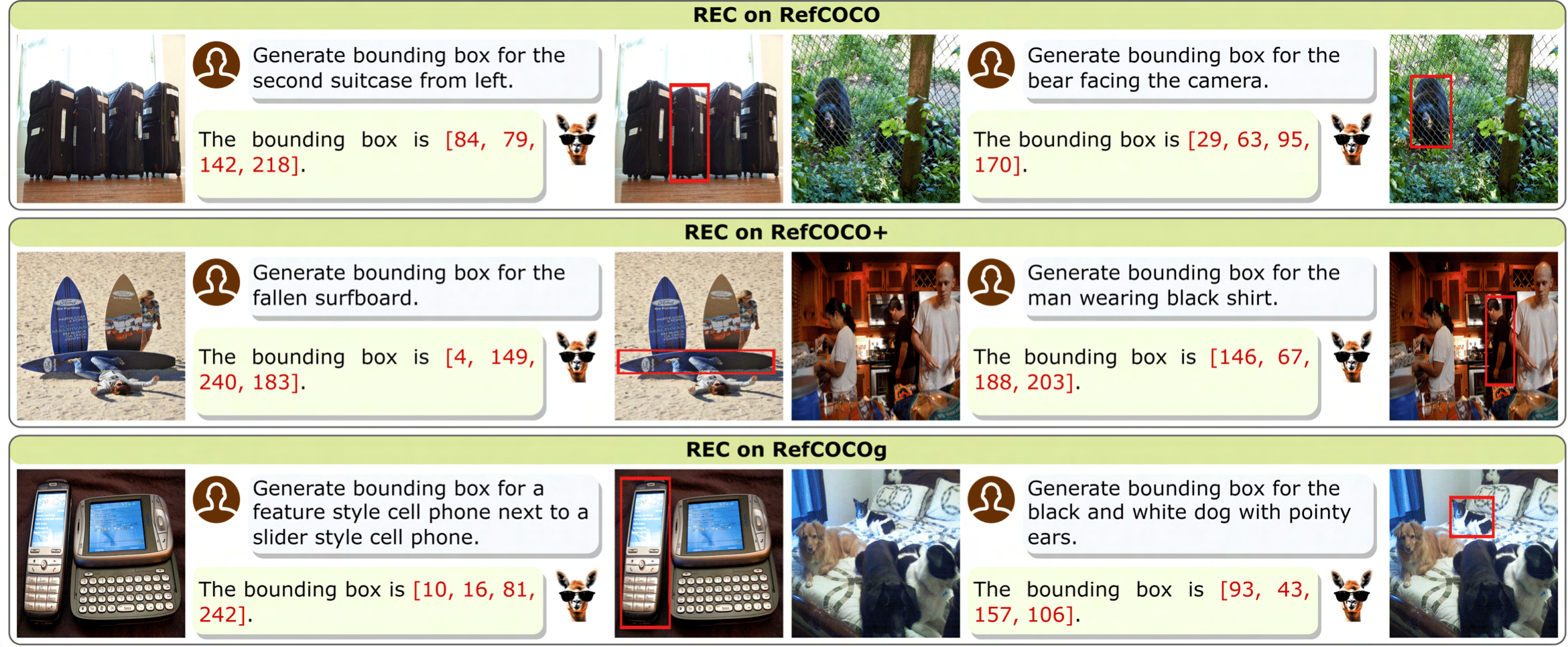
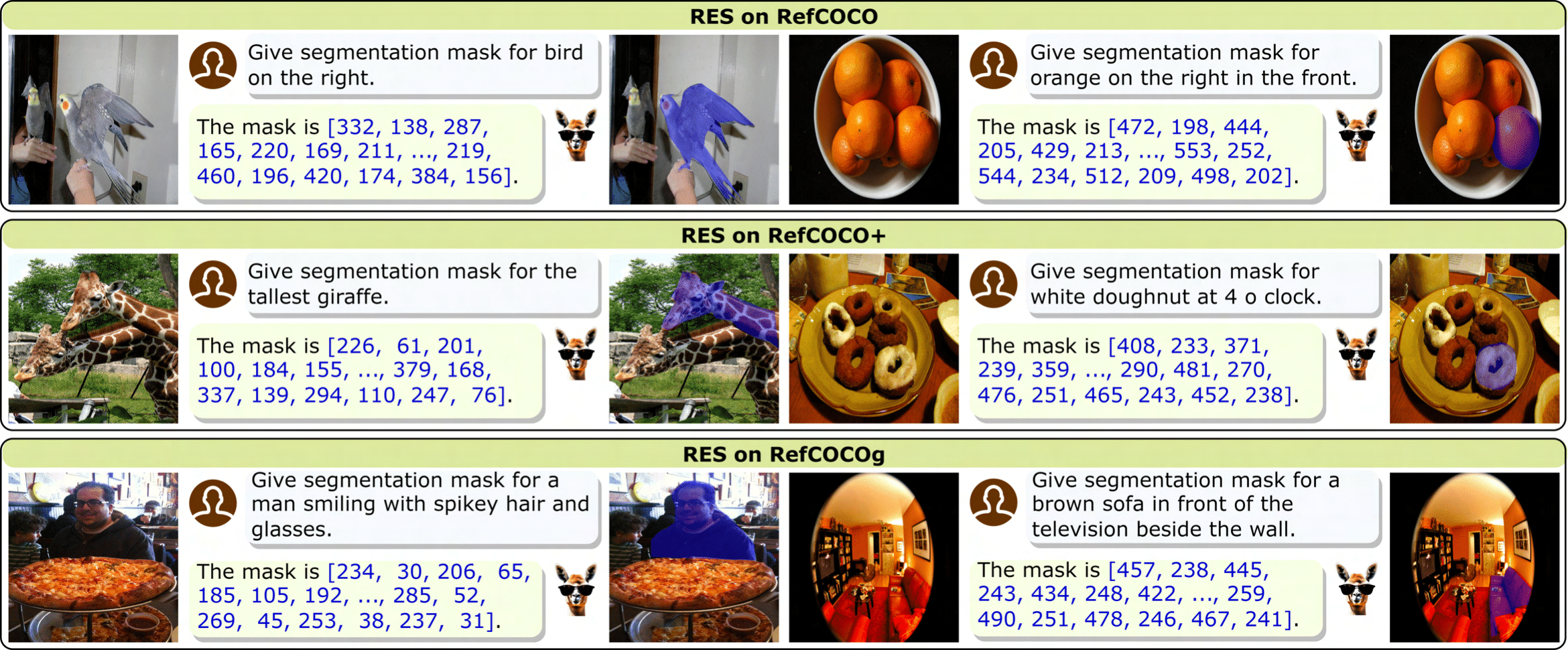
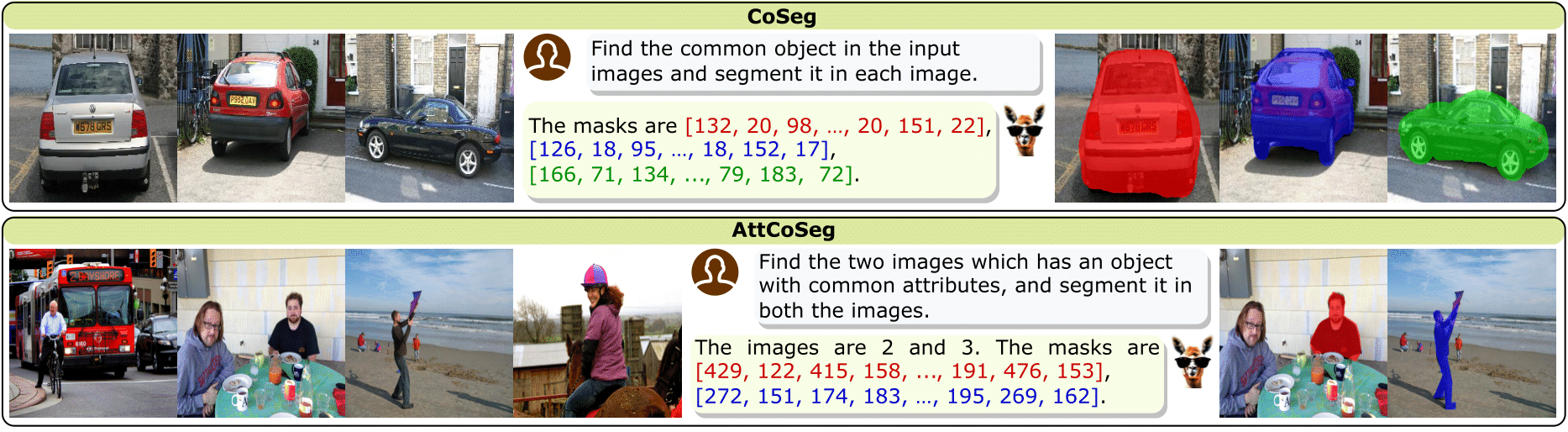
VistaLLM: We introduce VistaLLM, a powerful general-purpose vision system that integrates coarse- and fine-grained vision-language reasoning and grounding tasks over single and multiple input images into a unified framework.
Novel Sampling Algorithm: To efficiently convert segmentation masks into a sequence, we propose a gradient-aware adaptive contour sampling scheme, which improves over previously used uniform sampling by 3-4 mIoU scores on different segmentation benchmarks.
CoinIt Dataset: To train VistaLLM on a versatile form of vision and language tasks, we propose Coarse-to-fine Instruction-tuning) Dataset, which contains 6.8M samples